Dell Server Data Recovery: PowerEdge 2900 RAID 5 Data Loss
Table Of Contents
show
RAID 5: Overview
A RAID array connects two or more hard drives together to make what is essentially a single giant hard drive. RAID arrays offer greater storage capacity, protection against data loss from individual drive failure, increased efficiency, or some combination of the three.
A RAID-5 is a redundant array of independent disks which splits all of the data written to it and “stripes” it across all of the drives in the array. A single block of data in a RAID array is typically 128 sectors on a hard disk drive, or 64 kilobytes. Unlike RAID-0, which also uses this striping technique to link its drives together, a RAID-5 array also has “parity” blocks.
These special blocks hold bits of parity data so that if any single drive in the array fails, the RAID controller can use XOR logic to piece together the missing data. This parity data takes up a total of one drive’s worth of space in the array, regardless of how many drives are in the array. A RAID-5 array has one less drive’s worth of storage capacity than a RAID-0 with the same amount of equally-sized drives. However, multiple drive failures can still cause RAID 5 data loss.
RAID-5’s redundancy ensures data protection in the case of a single hard drive crash. If an IT technician gets notified and immediately replaces the failed hard disk and performs a RAID rebuild, a RAID 5 data loss will have been avoided. But if a second hard drive fails before the first drive can be replaced, the entire array will fall offline and the data will be irretrievable by normal means. Failure to replace a failed drive and run a RAID 5 rebuild to restore redundancy will result in RAID 5 data loss.
In this Dell PowerEdge 2900 data recovery scenario, two of the Seagate ST3250310NS hard drives in the client’s three-drive RAID-5 array had failed. While imaging the first failed hard drive, our engineers found that while the drive’s physical components were just healthy enough to read data, there were over 3,000 bad sectors, which had likely caused the drive’s failure.
This hard drive failure had occurred a while ago without the client noticing, and the parity stripes on the two remaining drives picked up the slack. We refer to the first drive in a RAID-5 array to fail as “stale” because the user has continued to write new data to the other drives in the array long after the drive has failed, and when the drive is resuscitated in our cleanroom, its contents will be out-of-date.
If a stale drive is forced back online by the user (assuming it can be), it can cause horrible data corruption as the RAID controller tries to incorporate the stale data into the array. When the RAID-5 array’s second drive’s condition became degraded and started exhibiting S.M.A.R.T. errors, the RAID controller forced that drive offline as well, bringing the operation of the entire array to a screeching halt.
Dell PowerEdge 2900 Data Recovery Case Study: Three-Drive RAID-5 Array
Total Capacity: 500 GB
RAID Level: 5
Drive Brand: Seagate Barracuda ES.2
Drive Model: ST3250310NS
Operating System: Windows Server 2008
Situation: One drive failed, second drive degraded
Type of Data Recovered: Word, Excel, Quickbooks, PDF, and Pictures
Gillware Data Recovery Case Rating: 9
This client had a Dell PowerEdge 2900 server running Windows Server 2008. The server was stocked with three 250-gigabyte Seagate Barracuda ES.2 enterprise-class hard drives arranged in a RAID-5 array. Two of the drives had failed causing the RAID 5 data loss. The client turned to us for our Dell PowerEdge data recovery services.
The Dell PowerEdge 2900 Data Recovery Process
In this Dell PowerEdge 2900 data recovery process, our cleanroom, logical, and RAID data recovery engineers all had important roles to play. After the disks in the RAID array had been imaged as completely as possible by our cleanroom data recovery engineers, our engineers pass the images over to our logical and RAID engineer Cody so that the data can be correctly arranged.
All drives in a RAID-5 array have a specific order they must go in so that the data makes sense. In this case, there were three drives in the array, so it was up to Cody to determine which disk was Disk 0, which was Disk 1, and which was Disk 2. Some occasional clients will send the drives in their RAID arrays to us fully labeled, but when they don’t, we have methods of figuring out which drive is which on our own.
After each hard drive had been imaged in the cleanroom, our engineers scanned the drives for metadata, and then handed their findings off to Cody’s department along with the images of the drives in the array. By studying the file system metadata and the RAID controller metadata on each hard drive, Cody could arrange the hard drives and see a pattern emerge. For this particular Dell PowerEdge 2900 data recovery case, the pattern of file system metadata Cody found looked a bit like this:
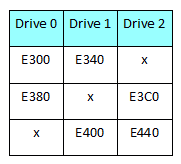
The file system metadata is displayed in hexadecimal. For those of you who do not speak hex, E300 is 58,112, E340 is 58,176, E380 is 58,240, E3C0 is 58,304, and so on. Analysis of these patterns is crucial to averting permanent RAID 5 data loss. The progression of metadata in this pattern told Cody how the data was striped across each disk as well as where the RAID array’s parity blocks were. There are a few different ways data can be striped in a RAID-5, some of which will offer small improvements in read or write speed or efficiency.
The Bitmap Method of RAID 5 Data Loss Analysis
The RAID controller does a lot of clever work to manage the RAID array, but it’s not smart enough to tell on its own if the disks are in the wrong order. And if they are in the wrong order, file pointers will point to the wrong file binary and all file contents will end up hopelessly garbled. Our RAID data recovery engineers have come up with a clever means of testing whether they’ve put together a RAID-5 array in the correct order, dubbed the “bitmap method”.
To imagine the bitmap method, think back to the heady old days of the Internet in the 90s, back when you couldn’t use your phone and surf the Web at the same time. When you went to a web page with a large image file on it, you could see the image slowly scroll into existence from top to bottom, because the beginning of an image file starts at the top and works its way down. Now imagine that somebody could cut up that image file on the website you’re browsing and then rearrange the pieces before your cutting-edge 56k modem could start reading the file. If that file was a photo of a person, that person’s legs could end up sandwiched between their head and their chest.
To use the bitmap method, our RAID-5 data loss engineers look for a large bitmap file with a beginning near the start of one block and a size at least as large as the total amount of blocks in one stripe. Bitmaps are uncompressed image files, so they work best for this test. If everything is in the right order, then the RAID has been put together correctly. If not, we congratulate the engineers for turning the group photo the client took at their last family reunion into Pablo Picasso’s Guernica.
Now that Cody had done all the hard work solving the geometry of the RAID array, averting this RAID 5 data loss was a simple matter. Since our engineers had gotten such great binary reads on the drives in the array, there was only a little additional file recovery work to be done after the client’s RAID-5 array was put back together. Cody pored through the files on the reconstructed RAID-5 array, testing the client’s valuable Quickbooks files and Office documents to make certain they were functional. We ended up rating this Dell PowerEdge 2900 data recovery case a high 9 on our ten-point scale.
How Can I Avoid RAID 5 Data Loss?
Our CEO Brian Gill has put together a list of best practices to extend the life of your RAID-5 array, but no matter how diligent you are with the upkeep, no RAID array can last forever. The best way to save the hard drives in your RAID array a trip to our data recovery lab when they fail is to actively maintain an offsite backup of all your critical data.
