RAID 10 Data Recovery
Even with a heavily-redundant nested RAID, your server can still crash. Whenever your server crashes, you’re in for a bad time, but Murphy’s Law always seems to be fully in effect, and it’s likely to happen at the worst possible moment. Fortunately, if a RAID 10 server crash catches you off-guard, and puts your organization in jeopardy, we can save you a lot of trouble. Gillware Data Recovery offers expert RAID 1o data recovery services.
Why Choose Gillware for RAID 10 Data Recovery?
Our RAID 10 data recovery staff are experts in their field. Our technicians have logged thousands of man-hours of data recovery experience and have dealt with just about every RAID setup under the sun. We’ve done things our competitors have told their customers were impossible. We’ve done things our competitors have said were possible at lower prices than those same competitors charge their customers.
We here at Gillware stand by our engineers’ skills and our financially risk-free RAID 10 data recovery services. If we can’t recover your critical data at a price that works for you or your organization, you don’t owe us a dime.
Don’t let your failed RAID 10 keep you from your important data.

The RAID 10 Data Recovery Process
So, how do our data recovery technicians here at Gillware Data Recovery recover data from a failed RAID 10 array?
Free Evaluation of Your Failed RAID 10 Array
As is our policy for data recovery services, the first thing we offer you here at Gillware is a totally financially risk-free RAID 10 data recovery evaluation. If you live in the continental United States, we are even happy to offer you a prepaid UPS shipping label to get your crashed RAID 10 array to us at no cost to you.
It’s important to send all of the disks in the array, including any hot spare disks. The RAID enclosure, controller card, and other hardware components, however, are completely unnecessary. Our RAID data recovery experts use custom software to emulate the RAID controller, so we’ll be able to access the RAID drives to recover data even if the problem is controller failure.
Once your crashed RAID 10 array has been evaluated, we present you with a price quote to recover data and our predictions for the case results. This is not a bill; we only need your promise that you are comfortable paying for our data recovery efforts in the event that we recover the data you need. We only continue on with the RAID 10 data recovery work if you approve our price quote.
Independent Analysis of the Hard Drives in Your Failed RAID 10 Array
Our data recovery experts assess the health of every hard drive in your crashed RAID 10 setup and make repairs to the drives’ electrical components, internal components, or firmware as needed, and use our proprietary data recovery software HOMBRE to create full forensic write-blocked images of all the drives in the array. This RAID recovery software was developed in-house by our data recovery software experts; we don’t recommend using a RAID recovery software solution of your own unless you’re willing to risk further data loss.
The images of the independent disks are contained on our internal customer data storage; these drives are never allowed outside our facility and are zero-filled according to Department of Defense standards after your data recovery case has been completed.
Determining the Physical Geometry of Your Failed RAID 10 Array
RAID 1+0 and RAID 0+1 arrays are complex RAID arrays. Essentially, they are two RAID configurations stacked on top of each other. Using HOMBRE’s relational database and the metadata contained on each of the independent disks in the failed RAID array, our RAID 10 data recovery technicians can puzzle out the way the hard drives in your RAID 10 have been arranged. After determining the striping size, striping pattern, data offset, and the order of the drives in the array, our engineers begin to have a clear picture of the data loss in the array.
Reuniting You with Your Data
After rebuilding the failed RAID 10 array with our disk images, our engineers analyze the lost data with the help of HOMBRE. We make as certain as we can that there is as little file corruption as possible and that your most critical data is functional.
We only bill you for our data recovery efforts after we’ve successfully recovered your data. Upon payment, we extract your recovered data to a new, healthy hard drive with hardware-level encryption for your security and ship your data back to you.
If you would like to contact us to receive a no-pressure consultation, click the button below. This will take you to a page with our phone number and email. This page also provides you with the option to schedule an appointment with a Client Advisor at a later time or date, or chat with them online.
Click the button below if you would like to send in your device. Sending in your device is financially risk-free. You will be asked to fill out a short form. Once you have completed the form, we will send a shipping label to the address provided. After we receive your device, we will begin a free evaluation and contact you with a firm price quote.
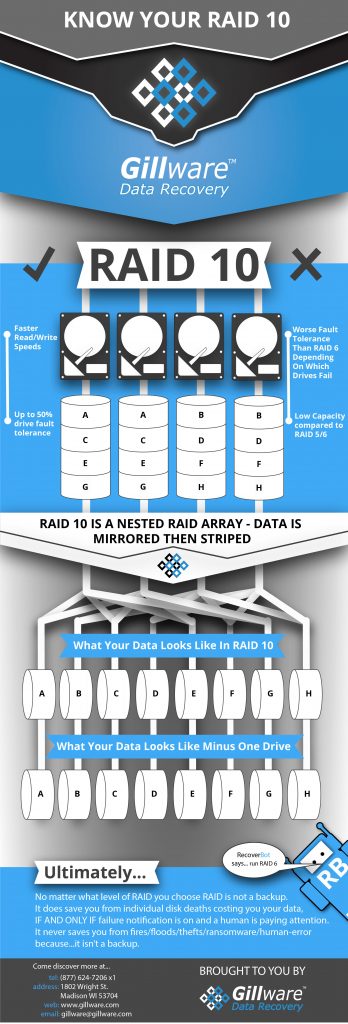
What Is RAID 10?
RAID 0 and RAID 1 make up, on their own, the simplest RAID levels. RAID 0 breaks up all of the data written to its disks into stripes. These stripes are usually 32 to 64 kilobytes in size. Any file larger than the stripe size gets broken up into pieces. RAID 0 creates a single volume as large as the combined capacity of all of the hard drives in the array. However, there is no fault tolerance whatsoever. If one hard drive goes down, the entire RAID array goes down with it.
RAID 1 usually only uses two hard drives. The RAID controller takes any changes made to one hard drive and copies them over to the other, making the contents of both hard drives exact duplicates of each other. If one hard drive fails, the other immediately takes its place. RAID 1 provides fault tolerance, but offers no increased capacity.
RAID 10, also known as RAID 1+0, combines RAID 0 and RAID 1 to offer the features of both configurations. Data is not only striped between multiple hard disks, but mirrored to an equal number of hard drives. This RAID configuration results in a nested RAID array with both increased capacity and fault tolerance in the event a single disk fails, like RAID 5 or RAID 6.
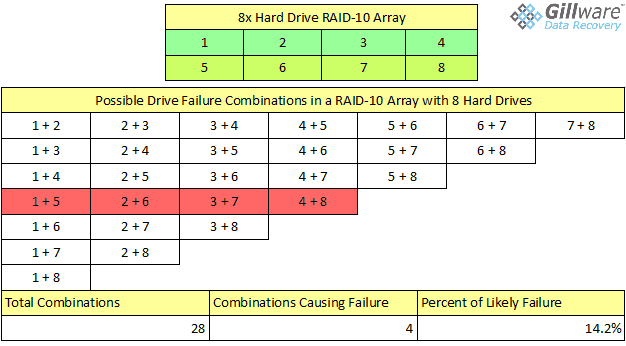
RAID 10 seems like a huge improvement over RAID 5 and RAID 6. No matter the size of the redundant array, you can, in theory, lose up to half your hard disks without having to deal with a RAID-10 crash. It seems quite unlikely you would ever need RAID 10 data recovery services in response to a RAID array data loss situation. But RAID 10 isn’t quite that reliable in practice – you may still need RAID data recovery services.
RAID 10 vs RAID 6
Take, for example, a simple, hypothetical four-drive RAID array combining RAID 0’s data striping with RAID 1’s disk mirroring. Despite having four disks, you only have two drives’ worth of usable capacity. But at least you have the peace of mind of knowing you can lose two disks and keep going, right?
Wrong. You could lose half of your hard drives in your RAID volume and not even notice—as long as you only lose the right two hard disks. If you lose two drives that contain the same data – both a set of “original” data and its mirrored copy – it’s game over. In this hypothetical four hard drive RAID 1+0 setup, there are six possible combinations of two drive failures in this array, two of which result in the RAID array failing. You have a 33% chance of two disk failures causing a RAID 10 crash and data loss.
Talk to Hard Drive Data Recovery Expert Today!

Our client advisors are available by phone during business hours
(M – F: 8am – 7pm; Sat: 10am – 3pm).

Send us an email including the type of phone you have and the problem you are experiencing. A client advisor will respond within 25 minutes during business hours
(M – F: 8am – 7pm; Sat: 10am – 3pm).

Have a quick question about the data recovery process? Use our chat feature to chat with one of our client advisors (not a robot!) during business hours
(M – F: 8am – 7pm; Sat: 10am – 3pm).

Want to schedule a call for a time that is convenient for you? Click the button above to schedule a brief consultation with one of our client advisors.
Click here to schedule a call
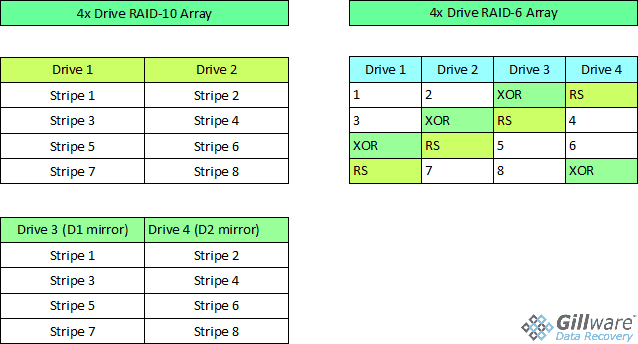
Contrast this with RAID 6. RAID 6 works very similarly to RAID 5, but has an extra layer of parity calculations. The extra parity takes up another disk’s worth of space, spread across the multiple disks in the array.
So, what if you take the four drives in the hypothetical RAID array and configure them in a RAID 6 array instead? Your RAID controller has to do some extra parity computations every time you write data, resulting in a bit of a performance hit. However, keep in mind that computers are really good at doing math, and doing it really quickly. It was their original raison d’être, after all.
Due to the way both parity layers are spread across all four hard drives in the RAID 6, you could lose any two drives before you have to start worrying about a RAID-6 crash. Our CEO Brian Gill recommends RAID-6 over RAID-10 for this exact reason.
Looking for a different type of data recovery?