Seagate Hard Disk Short DST Failed
Table Of Contents
show
Disk Self Testing: The Long and Short of It
There are two sorts of Disk Self Test or DST, procedures a hard drive can undertake to gauge its health. Both of these tests measure how well the hard drive is performing. DSTs are non-destructive tests, meaning they do not affect any of the user data actually stored on the hard disk platters.
The user can run either of these tests at their discretion using diagnostic software tools. If a hard disk shows signs of abnormal behavior, the user’s computer can also force the drive to undergo a self-test. When a hard drive fails either DST, it’s a sign that its physical condition has deteriorated. At the very least, the drive’s performance has dipped beneath its host computer’s minimum operational threshold.
Has your hard drive failed a short DST check?

What Is a Short DST?
A short DST quickly verifies that the major components of the hard disk drive—the read/write heads, ROM, electronic PCB, spindle motor, platters, etc.—are functional within optimal parameters. This short DST only takes a few minutes. During this time, the HDD is still usable, but its performance may slow down a bit.
Learn more about hard disk self testing
Data Recovery Software to recover
lost or deleted data on Windows
If you’ve lost or deleted any crucial files or folders from your PC, hard disk drive, or USB drive and need to recover it instantly, try our recommended data recovery tool.
Retrieve deleted or lost documents, videos, email files, photos, and more
Restore data from PCs, laptops, HDDs, SSDs, USB drives, etc.
Recover data lost due to deletion, formatting, or corruption

What Is a Long DST?
A long or extended DST is a more in-depth test than the short DST. In addition to the brief testing of the hard disk’s physical components, the long DST scours over the hard disk platters to pick out bad sectors and problematic areas of the disks. If it finds any bad sectors, it automatically takes steps to reallocate data and re-map the logical sectors contained in problematic areas to healthier sections of the disk.
When S.M.A.R.T. Testing Isn’t Always That Smart
Hard disk drives all use S.M.A.R.T. (Self-Monitoring, Analysis, and Reporting Technology) to keep track of their own health. S.M.A.R.T measures a wide variety of operating parameters. These parameters range from read error rates and seek time performances to the internal temperature of the drive. The goal of S.M.A.R.T is to anticipate hard disk failure and shoot off some digital warning flares to the user if need be.
Unfortunately, S.M.A.R.T isn’t always as helpful as intended. While S.M.A.R.T is standardized to some extent among HDD manufacturers, many attributes are still vendor-specific and are not extensively documented. In addition, due to the lack of full standardization, the hard drive can have difficulty relaying its findings, even if the computer has a S.M.A.R.T-enabled motherboard. Essentially, any red flags your hard drive may shoot up through its internal S.M.A.R.T testing may go wholly unnoticed—no matter how dire.
Another disadvantage of S.M.A.R.T. is that as the tests grow more intensive and complex, they can actually cause the hard drive’s firmware—sort of the drive’s own hidden “operating system”—to develop glitches. Severe firmware glitches can cause a hard drive to die, requiring attention from firmware repair specialists in a data recovery lab.
The client in this case came to our Seagate hard disk repair specialists when their PC stopped booting. The drive failed a short DST test at startup. And instead of the familiar Windows logo, our client saw a boot error message reading, “No boot disk has been detected or disk has failed.”
The client tried to test the hard drive’s health using SeaTools, Seagate’s hard disk diagnostic software. The drive hadn’t raised any red flags in S.M.A.R.T., the self-testing system hard disk drives use to report on their own status and predict hard drive failures. However, the client’s Seagate hard disk drive still failed any disk self checks.
After checking to see if the hard drive’s SATA connection cables had come loose or worn out to no avail, the client knew that their only chance of retrieving any files lay in the hands of hard drive repair specialists like the ones here at Gillware Data Recovery.
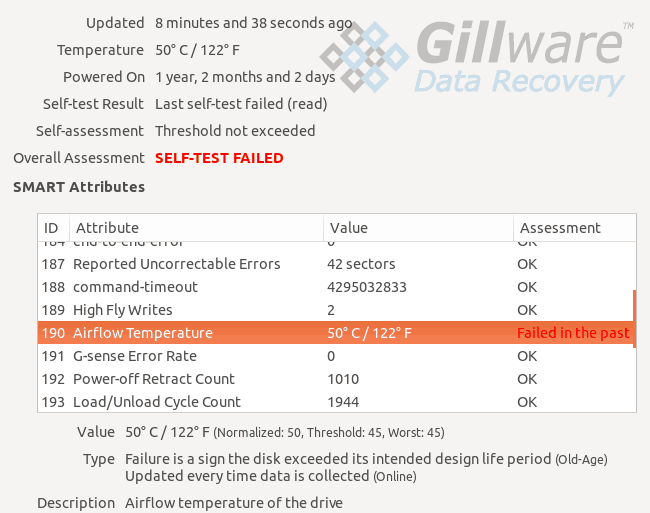
Drive Model: Seagate ST100DM003
Drive Capacity: 1 TB
Operating/File System: Windows NTFS
Data Loss Situation: No SMART alerts, but short DST test failed; boot error message “No boot disk has been detected or disk has failed.”
Type of Data Recovered: User profiles and documents
Binary Read: 6.1%
Gillware Data Recovery Case Rating: 9
Seagate Hard Disk Repair Results
Our Seagate hard disk repair specialists brought this failed hard drive into our cleanroom lab for repair. Our engineers found the drive just barely clinging to life, with its read/write heads on the verge of catastrophic failure.
With deft hands and careful manipulation of our proprietary, fault-tolerant data recovery software, our engineers could salvage data from this hard drive without replacing its read/write heads. Our software also provided our engineers with the ability to strategically target the disk’s file system metadata and used area, allowing us to use what little life the failing read/write heads had left to dredge data up from the crashed hard drive.
After reading only 6.1% of the hard drive’s sectors, our engineers successfully recovered 99.9% of the files from the drive. At this point, the hard drive’s beleaguered read/write heads breathed their last gasp. They survived just long enough for our Seagate hard disk repair specialists to pull out all of our client’s documents. We ranked this data recovery case a high 9 on our ten-point data recovery case rating scale.
If you still have questions regarding our recovery process or pricing
