RAID 5 Video Demonstration: Salvaging Data with a Stale Drive
In this RAID 5 video blog, Brian Gill breaks down one of our recent RAID 5 data recovery cases. Our client sent in a 3 drive RAID 5 array for data recovery. One hard drive was perfectly healthy. However, two other hard drives had failed. One of the drives had massive platter damage and was completely nonrecoverable. Most of the magnetic substrate on its platters containing the client’s data had been reduced to a fine powder. The third drive had a failed spindle motor.
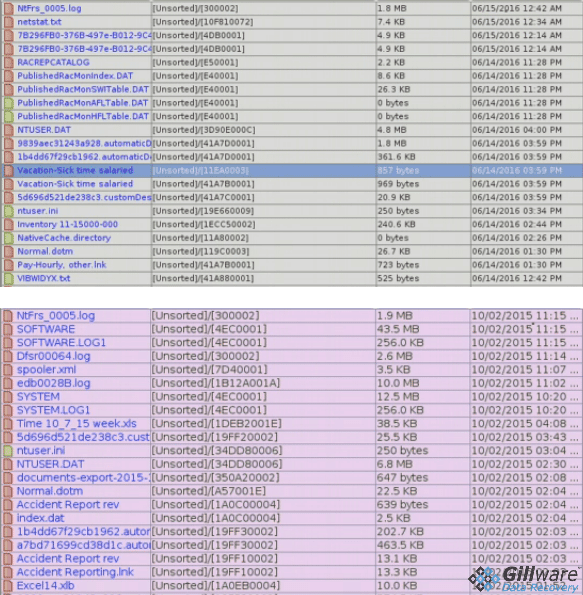
The drive with the failed spindle motor had failed eight months ago, and the RAID array had been running minus one drive since then. RAID level 5 uses XOR functions to reconstruct lost data in case one drive in the array fails. When a RAID 5 array continues to run after one drive fails, we say the RAID has been running in a “degraded” condition. No data has been lost, but the array is a vulnerable state.
The hard drive that had failed eight months ago was the only one of the two failed hard drives that could be resuscitated. The only option for our data recovery technicians was to put the RAID array back together using the healthy drive and the stale drive.

Having to recreate a RAID 5 array using a stale hard drive is hardly an ideal circumstance for our data recovery technicians. As Brian demonstrates, the stale drive causes any data written to the array since the beginning of the “stale epoch” to become corrupted. In this case, the stale epoch began in October and lasted until the second drive failed in June.
In this video, Brian discusses how RAID 5’s XOR parity calculations try to reconstruct the data on a failed RAID array using one healthy drive and one stale drive, and how data can become corrupted as a result. Unfortunately, there’s no way around having to use the stale drive in this particular case. As a result, only a small fraction of the data created during the RAID 5 array’s stale epoch will be usable.
RAID 5 Video Demonstration: Salvaging Data with a Stale Drive
